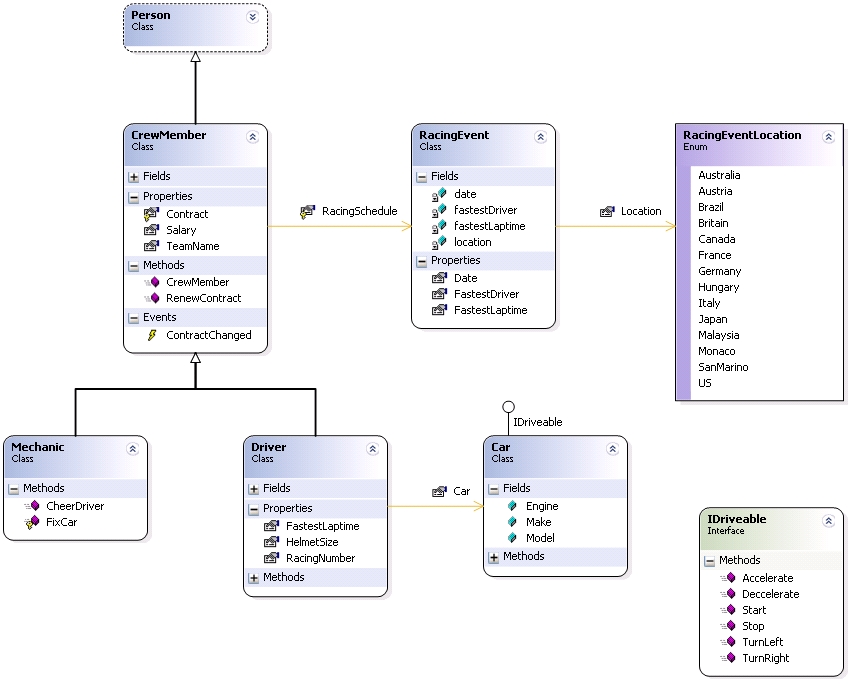
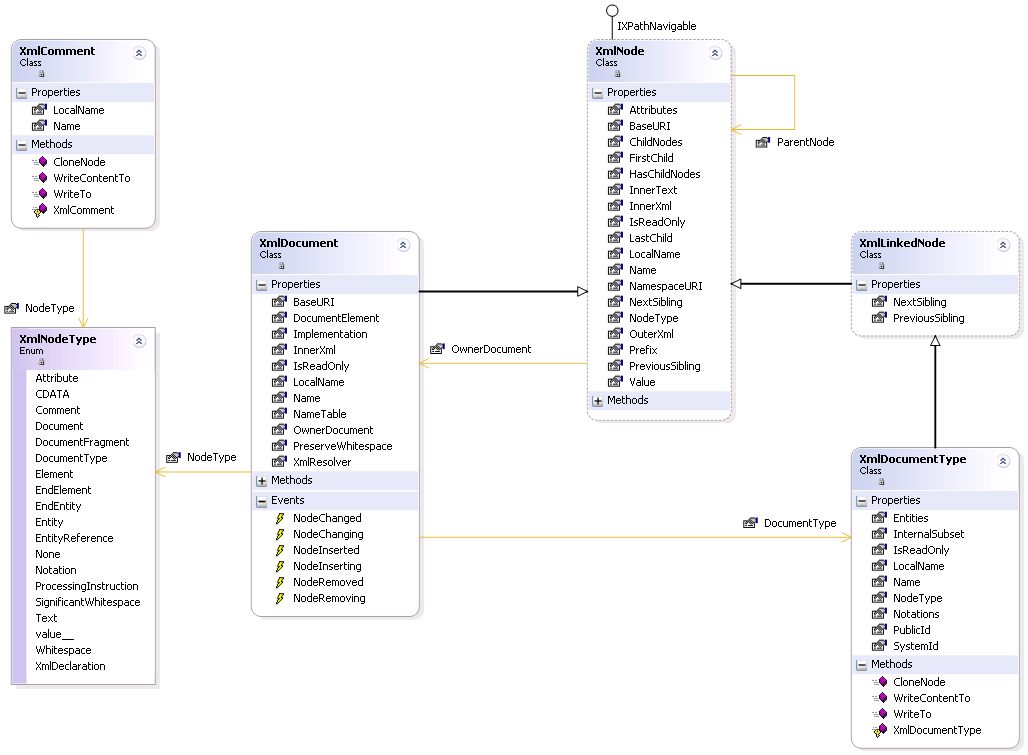
Keith posted a couple of screenshots of the Whidbey class designer a few weeks ago. Two things about this designer leapt out at me. First, it’s not a UML class designer (though it borrows heavily from UML’s graphical syntax). Second, it doesn’t provide much abstraction over the raw code. This lead me to think about the role of class modeling in the analysis and design process. How similar are the analysis and design models? UML doesn’t have an analysis model syntax, so typically the analysis phase uses the class diagram as well, but with less details. Are design models just analysis models with more details? Or is there a need / opportunity for higher-abstraction analysis modeling separate from (but transformable to) design models?
{kind=link}
{kind=link}
(Note, much of my thinking expressed in this post comes from a discussion with my father. If you read Pat’s blog, you know that Dad’s an architect for the FAA. Not that he agrees with me – actually, just the opposite. I also discussed this at length with an ex-teammate Tim Mallalieu. I’m hoping they’ll both respond in the comments since neither has their own blog…yet.)
I’m a big fan of Ivar Jacobson’s book Object Oriented Software Engineering – it’s one of the few on my office bookshelf. However, like many OO methodologies, dealing with the relational database is mostly left as an exercise for the user. In a 500+ page book, Jacobson dedicates a scant 15 pages on the topic of persisting objects in a relational database. Fowler acknowledges this in PoEAA when he points out that the database is often treated like the “crazy aunt who’s shut up in an attic and whom nobody wants to talk about” in OO design. However, in almost all enterprise development today, the database is a reality and a process that doesn’t formally deal with databases is fundamentally incomplete. That also means that the database needs to be included in the model.
From my experience, you typically start including the database in the model during the design phase. In the analysis phase, I want to work at a higher level of abstraction. Jacobson writes about Entity, Boundary and Control objects. Entity objects are used to model long-lived information – i.e. information that is stored in the database. Entities share a lot of similarities with classes – they have names, methods, and associated state – but are built at a higher level of abstraction. By ignoring implementation details (like database persistence strategy) you can focus better at the problem at hand. When you move from analysis to design, entities get mapped to both code design elements (classes, interfaces, enumerations, etc) and database design elements (tables, procs, views, etc).
This mapping from analysis to design is influenced by several decisions. Fowler details three domain logic patterns in PoEAA: Domain Model, Transaction Script and Table Module. Your pattern choice has profound implication on your design model. Only when you use the domain model pattern is there a one-to-one mapping between entity analysis objects and class design objects. If you use the other patterns, that one-to-one mapping doesn’t exist. Transaction scripts don’t keep any state across method invocations and table modules are built as collections rather than distinct objects. To me, this implies that analysis and design models are fundamentally different and differentiated by more than the level of detail.
Furthermore, the analysis to design mapping is influenced by the kind of data represented by your entities. The Information & Application Architecture talk from the Architecture Strategy Series discusses four types of data: Request/Response (i.e. messages), Activity-Oriented, Resource-Oriented and Reference. Each has different usage and representation semantics. Reference and message data is read-only and almost always represented in XML. Reference data is also version-stamped. Activity and resource oriented data are private to the service and almost always stored in relational tables. However, resource-oriented data is usually highly concurrent while activity-oriented data is not. These differences in data semantics implies different design models for my entities. For example, O/R mapping works great for read-only and low concurrent data but not well for highly concurrent data. Again, the lack of one-to-one mapping implies a true difference between analysis and design models.
Personally, I’d like an analysis-domain-specific language to build my entities in (as well as my controls and boundaries). I’d also like to indicate what type of data each entity represents. When I map that model into the design model, I’d like to choose my domain logic strategy. The output of this mapping process would be both a class design model and a database design model based on the analysis model, the kinds of data in the analysis model as the persistence strategy chosen. In a perfect world, the design would be generated from the analysis model auto-magically. However, since I believe in Platt’s Second Law, I’m not sure generating the design model is particularly feasible. I guess when I get my hands on the Whidbey modeling engine, I’ll get a chance to find out.
Comments: