If you were intrigued by my Software Factories post last week, you might want to consider attending OOPSLA ’04. It’s in Vancouver this year, making it an easy trip from Seattle for me. There’s going to be an all-day tutorial on Using Domain Specific Languages, Patterns, Frameworks and Tools to Assemble Applications presented by the authors of Software Factories. There’s also a half-day tutorial on Generative Software Development presented as part of the Generative Programming and Component Engineering ’04 conference, which is co-located with OOPSLA ’04. OOPSLA will also feature talks by Rick Rashid, Steve McConnell, Ward Cunningham and Herb Sutter. And I’m not quite sure what this is about, but Jaron Lanier will be presenting a keynote entitled: “Exocomputing in the Year 2304: A Survey of Confirmed Alien Information Technologies”. I’ve got to check that out, if just to see what confirmed alien information technologies look like.
Software Factories Coming Soon
Now that Tech·Ed is over, I’ve got some time for things like playing Xbox, yard work and reading. I just finished The Footsteps of God (not bad, but not great – fine for airplane reading below 10,000 feet and after my battery died). On the technical side, I’ve been rereading ATL Internals for a COM based coding project I’m working on in my nearly-non-existent spare time. I also just started Software Factories by Keith Short and Jack Greenfield (with contributions by Steve Cook and Stuart Kent). Keith and Jack are architects in the Visual Studio Enterprise Tools Group. They are responsible for driving Microsoft’s model based development tools initiative and are heavily involved in the creation of the Whitehorse tools. Software Factories isn’t available yet – access to an early electronic copy is one of the perks of knowing the authors and having one of them speak as part of my Tech·Ed track.
Software Factories is about approaching application development with an industrialized manufacturing mindset, rather than the hand-crafted mindset we have today. It’s interesting how well this dovetails with Pat’s Metropolis work – both draw parallels to and learn from the Industrial Revolution. To quote from the website:
The industry continues to hand-stitch applications distributed over multiple platforms housed by multiple businesses located around the planet, automating business processes like health insurance claim processing and international currency arbitrage, using strings, integers and line by line conditional logic. Most developers build every application as though it is the first of its kind anywhere.
Without significant changes in our methods and practices, global demand for software development and maintenance will vastly exceed the pace at which the industry can deliver in the very near future.
Scaling up to much higher levels of productivity will require the ability to rapidly configure, adapt and assemble independently developed, self describing, location independent components to produce families of similar but distinct systems. It will require a transition from craftsmanship to manufacturing like the ones we have seen in other industries, and will eventually produce more advanced earmarks of industrialization, such as supply chains, value chain integration and mass customization.
We must synthesize…key innovations in software development…into a cohesive approach to software development that can learn from the best patterns of industrialized manufacturing.
This is what we mean by Software Factories. The industrialization of software development.
The book is fascinating, and I only just got started. The book should be available soon. Going forward, you can expect coverage on Architecture Center, as well as the official Software Factories website. In the meantime, keep an eye on Keith’s blog, check out this piece from the Architecture Center Update as well as this article on domain-specific languages, and watch Keith’s session from The Architecture Strategy Series.
Modelling Links
Michael has posted a great list of modelling links on his blog. I hadn’t realized Ramesh Rajagopal was blogging. Ramesh works on the class designer I blogged about last week.
Michael also has links to MSFT’s Dynamic Systems Initative. Since I came from the developer camp, I usually focus on application architecture. DSI is going to be crititcal to infrastructure architecture. We have a section on infrastructure architecture on the Architecture Center that includes more info on DSI.
Update: Michael linked to a two partinterview with Keith about the Whidbey modelling tools. Highly recommended.
Analysis vs. Design Modeling
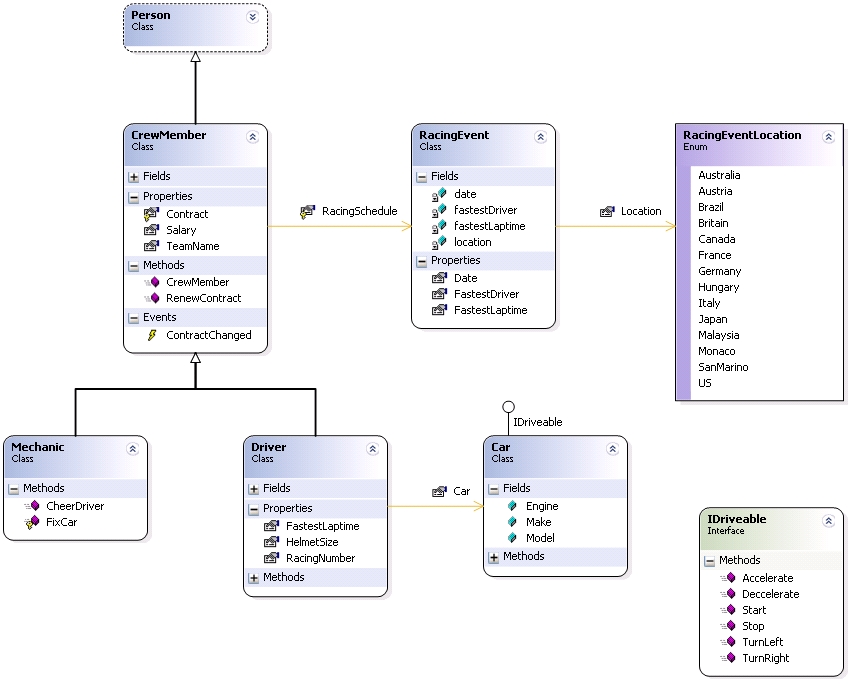
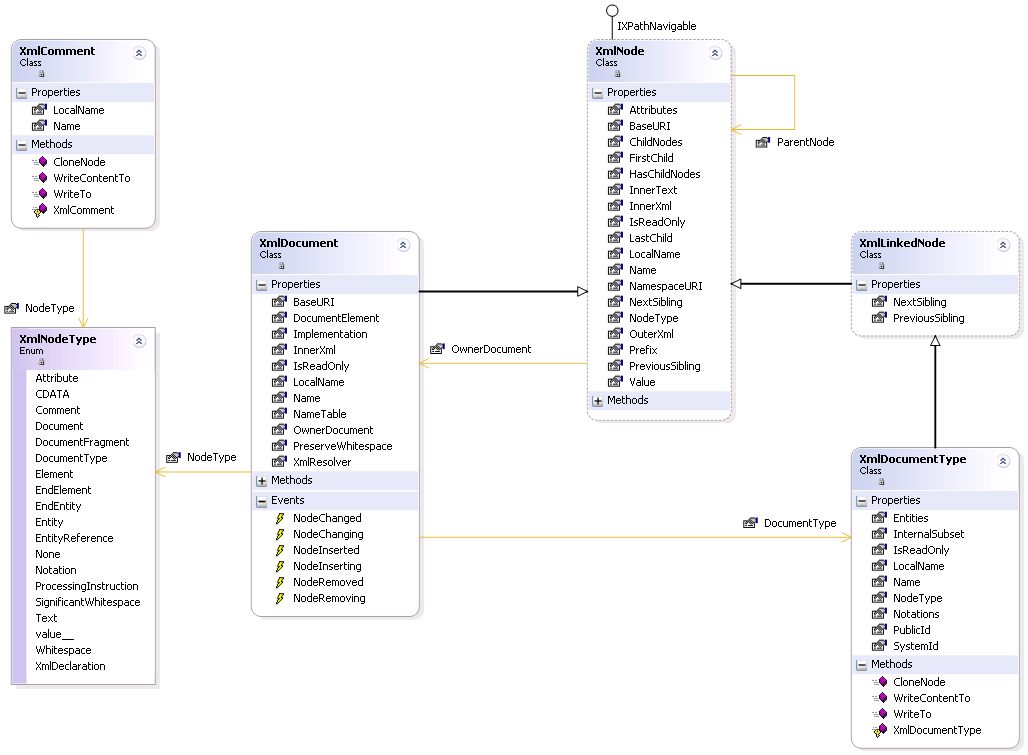
Keith posted a couple of screenshots of the Whidbey class designer a few weeks ago. Two things about this designer leapt out at me. First, it’s not a UML class designer (though it borrows heavily from UML’s graphical syntax). Second, it doesn’t provide much abstraction over the raw code. This lead me to think about the role of class modeling in the analysis and design process. How similar are the analysis and design models? UML doesn’t have an analysis model syntax, so typically the analysis phase uses the class diagram as well, but with less details. Are design models just analysis models with more details? Or is there a need / opportunity for higher-abstraction analysis modeling separate from (but transformable to) design models?
{kind=link}
{kind=link}
(Note, much of my thinking expressed in this post comes from a discussion with my father. If you read Pat’s blog, you know that Dad’s an architect for the FAA. Not that he agrees with me – actually, just the opposite. I also discussed this at length with an ex-teammate Tim Mallalieu. I’m hoping they’ll both respond in the comments since neither has their own blog…yet.)
I’m a big fan of Ivar Jacobson’s book Object Oriented Software Engineering – it’s one of the few on my office bookshelf. However, like many OO methodologies, dealing with the relational database is mostly left as an exercise for the user. In a 500+ page book, Jacobson dedicates a scant 15 pages on the topic of persisting objects in a relational database. Fowler acknowledges this in PoEAA when he points out that the database is often treated like the “crazy aunt who’s shut up in an attic and whom nobody wants to talk about” in OO design. However, in almost all enterprise development today, the database is a reality and a process that doesn’t formally deal with databases is fundamentally incomplete. That also means that the database needs to be included in the model.
From my experience, you typically start including the database in the model during the design phase. In the analysis phase, I want to work at a higher level of abstraction. Jacobson writes about Entity, Boundary and Control objects. Entity objects are used to model long-lived information – i.e. information that is stored in the database. Entities share a lot of similarities with classes – they have names, methods, and associated state – but are built at a higher level of abstraction. By ignoring implementation details (like database persistence strategy) you can focus better at the problem at hand. When you move from analysis to design, entities get mapped to both code design elements (classes, interfaces, enumerations, etc) and database design elements (tables, procs, views, etc).
This mapping from analysis to design is influenced by several decisions. Fowler details three domain logic patterns in PoEAA: Domain Model, Transaction Script and Table Module. Your pattern choice has profound implication on your design model. Only when you use the domain model pattern is there a one-to-one mapping between entity analysis objects and class design objects. If you use the other patterns, that one-to-one mapping doesn’t exist. Transaction scripts don’t keep any state across method invocations and table modules are built as collections rather than distinct objects. To me, this implies that analysis and design models are fundamentally different and differentiated by more than the level of detail.
Furthermore, the analysis to design mapping is influenced by the kind of data represented by your entities. The Information & Application Architecture talk from the Architecture Strategy Series discusses four types of data: Request/Response (i.e. messages), Activity-Oriented, Resource-Oriented and Reference. Each has different usage and representation semantics. Reference and message data is read-only and almost always represented in XML. Reference data is also version-stamped. Activity and resource oriented data are private to the service and almost always stored in relational tables. However, resource-oriented data is usually highly concurrent while activity-oriented data is not. These differences in data semantics implies different design models for my entities. For example, O/R mapping works great for read-only and low concurrent data but not well for highly concurrent data. Again, the lack of one-to-one mapping implies a true difference between analysis and design models.
Personally, I’d like an analysis-domain-specific language to build my entities in (as well as my controls and boundaries). I’d also like to indicate what type of data each entity represents. When I map that model into the design model, I’d like to choose my domain logic strategy. The output of this mapping process would be both a class design model and a database design model based on the analysis model, the kinds of data in the analysis model as the persistence strategy chosen. In a perfect world, the design would be generated from the analysis model auto-magically. However, since I believe in Platt’s Second Law, I’m not sure generating the design model is particularly feasible. I guess when I get my hands on the Whidbey modeling engine, I’ll get a chance to find out.
Custom Modeling Languages
It sure has been quiet around here. I spent last week on the road in Washington DC and Orlando at the federal and eastern region architect forums. Since my parents live in DC, Julie and Patrick came too. Nine days on the road with the family is hard, but it was worth it. Lots of fun, including Patrick’s first hockey game (even though the officiating was awful).
I spent a lot of time with customers talking about SOA and architecture frameworks. The frameworks talks were most interesting given Microsoft’s view on modeling languages in general, Whidbey’s design tools and our work on domain-specific models for distributed applications. To me, the most interesting thing is not the modeling tools shipping in the box with Whidbey, rather the modeling infrastructure. Accepting the idea of domain specific modeling means accepting that there are a vast number of different modeling languages – more than Microsoft could ever create on our own. In his solution architecture strategy series presentation, Keith Short talked about the need for a designer infrastructure and tool extensibility. He also confirmed that the Whidbey modeling tools are themselves built on a general modeling engine and framework. This modeling infrastructure enables the definition of new meta-models, extensions to existing meta-models and transforms between meta-models. It also has a synchronization engine for keeping artifacts at different levels of abstraction in sync (e.g. updating the model updates the code and visa versa). I’m not sure how much of this infrastructure will surface publicly in Whidbey, but Keith specifically said the modeling engine is a “piece of work that, over time, we hope to be able to offer both to our partners and customers so that you can build [modeling] tools yourself.”
This idea of building domain-specific modeling languages and tools feels pretty powerful to me. Besides the ones included in Whidbey (and the the previously discussed service-oriented language) what other languages would you like to see / use / design?